


April 30-May 4, 2018
The Social Science Methods Week (SSMW) consists of a series of workshops on methodologies with high potential to improve and advance research in the social sciences. Workshops are taught by expert methodologists drawn from departments across the social sciences at the University of Toronto. SSMW is an interdisciplinary forum where researchers can upgrade their methodological toolkit and build cross-disciplinary ties to like-minded scholars.
Registration is free, and open to graduate students and faculty at the University of Toronto. Participants can register for as many workshops as they wish, though enrollment for each workshop is capped at 20 participants. Lunch will be provided each day for registered participants.
Participants should bring a laptop to the workshops with any necessary software pre-installed.
All workshops will be held in the Department of Sociology, St. George Campus, located at 725 Spadina Ave, Toronto, ON M5S. We gratefully acknowledge the support of the Sociology Department in providing space for this event and lunch for the participants.
Questions can be directed to andrew.miles@utoronto.ca, or chang.lin@utoronto.ca.
Schedule of Workshops
| Monday, April 29 | Tuesday, April 30 | Wednesday, May 1 | Thursday, May 2 | Friday, May 3 | |
|---|---|---|---|---|---|
| Morning | 10 am - 12 pm Introduction to Python | 9 am - 12 pm R Basics: Analyzing and Plotting Data | 9 am - 12 pm Registered Report in Behavioral Science: A How-to Guide and Description of Benefits for Scientific Progress | 9 am - 12 pm Multilevel Modeling: An Introduction | 9 am - 11:30 pm Hearing Silence in Qualitative Interviews |
| Lunch Break | 12 pm - 1 pm | 12 pm - 1 pm | 12 pm - 1 pm | 12 pm - 1 pm | 12 pm - 1 pm |
| Afternoon | 1 pm - 5 pm Qualitative Social Science: A Fun Overview | 1 pm - 4 pm Measuring Theoretical Constructs with Unobserved Variables: An Introduction to Structural Equation Modeling | 1 pm - 4 pm Integrated Network Science: Social Network Analysis with R | 1 pm - 4 pm Introduction to Web Scraping and APIs with Python | 1 pm – 4 pm Models of Social Change: Methods and Principles of Age-Period-Cohort Analysis |
Workshop Descriptions
Time Use: Data, Analysis, and Applications
Length: 3 hours
Instructor: William Michelson, Department of Sociology
Data on how people use their time is becoming increasingly available. This workshop provides an overview of time use theory and methods, along with several applied examples. Topics include the structure of time-use data, analysis and presentation of time-use data, and how to access time-use data at the University of Toronto. Workshop participants will also engage in hands-on exploration of time-use data.
Introduction to R
Length: 4 hours
Instructor: Max Barranti, Department of Psychology
In this workshop we will cover how the basics of how to use R and RStudio. This workshop is designed for students who are interested in using R for data management, analysis, and/or graphing but who are unfamiliar with the R language and/or computer languages in general. We will discuss general procedures and principles for reading, manipulating, analyizing, and graphing data using R. Please come to the workshop with R and Rstudio installed on your computer.
Overcoming Blind Spots in Self-Knowledge: Research Methods for Improving the Validity of Self-Reports
Length: 3 hours
Instructor: Erika Carlson, Department of Psychology
By the end of this workshop, you should be familiar with the major limitations of relying on self-report data and have tools for overcoming these limitations. Specifically, you will use statistical software (R Studio) to model self-report data in more valid ways, and we will discuss how to use other sources of data to better measure what people are like (e.g., peer reports, experience sampling, and behavioural data). Prior knowledge of the generalized linear model and structural equation modeling is helpful but not required.
Dealing with Missing Data
Length: 4 hours
Instructor: Andrew Miles, Department of Sociology
This workshop provides a brief overview of the problems caused by missing data, and the options available for addressing them. It then focuses on multiple imputation, a powerful and widely used missing data technique. Workshop participants will learn how multiple imputation works, and gain practical experience in conducting basic statistical analyses using multiple imputation. Examples and exercises will be presented in Stata, but code will also be provided for R and SPSS. Workshop participants should come with their chosen software package preloaded on a laptop computer. This course is suitable for anyone familiar with regression analysis.
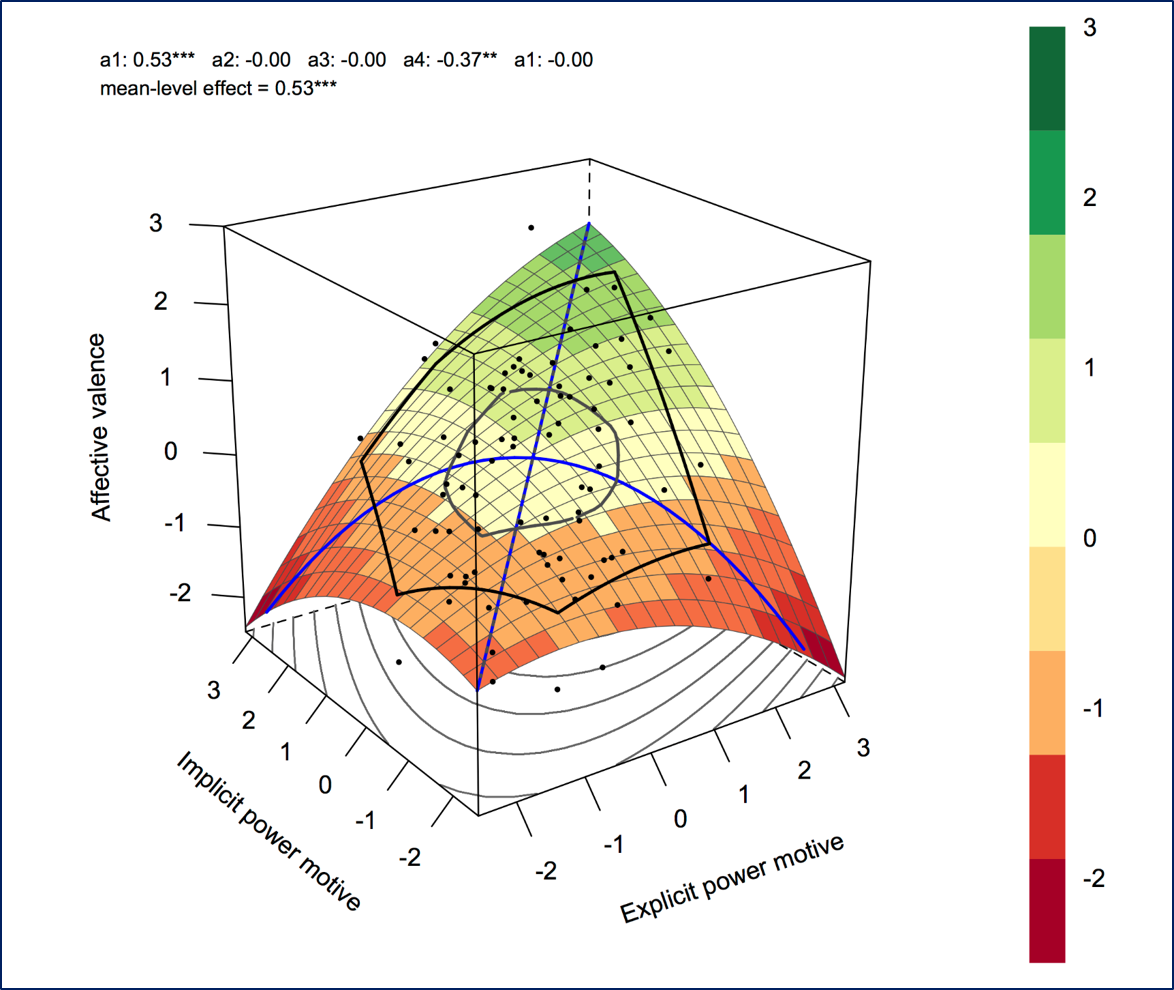
How to Test Questions About Similarity: Description and Empirical Demonstration of Response Surface Analysis
Length: 3 hours
Instructor: Stéphane Côté, Rotman School of Management
Participants should take this course if they are interested in testing hypotheses about the effects of similarity, matching, or fit on criteria (e.g., performance, well-being, leadership emergence). Examples of hypotheses that can be tested include: Do similar individuals like each other more or less than do dissimilar individuals? Are individuals who can accurately evaluate other people’s personalities more adjusted than individuals who form less accurate judgments of others? Are individuals who know their levels of cognitive and emotional abilities more successful than people who over- or under-estimate their levels of abilities? Participants will be able to test these hypotheses using analytical tools that circumvent the major limitations of traditionally used techniques such as difference scores. Participants should have a good understanding of regression analysis. Participants should also be familiar with R and be able to load data and run syntax in R.
Participants should have R and R studio installed on their computers. The RSA package for R should be installed.
Participants should read the following paper prior to the course:
Barranti, Maxwell, Erika N. Carlson, and Stéphane Côté. 2017. “How to Test Questions About Similarity in Personality and Social Psychology Research: Description and Empirical Demonstration of Response Surface Analysis.” Social Psychological and Personality Science 8(4):465–75.
Introduction to Qualitative and Historical/Archival Methods
Length: 4 hours
Instructors: Ashley Rubin, Department of Sociology
This course will provide a brief introduction to qualitative methods, from questions about research design to specific tools of analysis, with extended examples from historical and archival research.
An Introduction to Machine Learning for Textual Analysis
Length: 2 hours
Instructor: Ludovic Rheault, Department of Political Science
This workshop offers a pragmatic introduction to supervised machine learning, with a focus on problems involving textual data. Machine learning is a central component of modern applications interacting with human language, from computer-assisted translation to intelligent personal assistants. With the growing availability of digitized texts on the web, machine learning techniques have also become useful to build predictive models in the social sciences. The workshop introduces participants to fundamental concepts in supervised learning, with an overview of models commonly used for textual analysis such as support vector machines. The second half of the workshop will illustrate the methodology with a concrete application: sentiment analysis using social media data. The practical examples rely on Python 3, which is free to use. Interested participants can choose to follow along if they install Python on their laptops or a prepackaged distribution like Anaconda. Some familiarity with statistics (in particular, an understanding of generalized linear models) and programming will be helpful to benefit from the workshop.
Introduction to Multilevel Models
Length: 4 hours
Instructor: Elizabeth Page-Gould, Department of Psychology
Multilevel modeling (MLM) is a statistical analysis that can analyze datasets when cases are not independent, like data from multiple family members or longitudinal studies. Moreover, MLM is a flexible analysis that can be learned once and readily adapted to most research designs that require it. For researchers who are used to working with Repeated-Measures ANOVA, MLM offers an improved method for harnessing the statistical power of within-subjects and nested designs and can easily incorporate continuous predictors. This workshop will provide a practical introduction to MLM, including advanced topics like growth curves, non-Gaussian data, cross-classified models, and the calculation of effect sizes. Workshop materials will include example data and syntax for SPSS, R, and STATA. The goal is for you to leave the workshop with the theoretical and practical knowledge you need to immediately begin analyzing your data with MLM.
Introduction to Web Scraping and APIs with Python
Length: 2 hours
Instructor: Fedor Dokshin, Department of Sociology
The Internet has opened new opportunities for social research. Social media websites record rich digital traces of our social behaviour online. Besides records of online activity, the Internet also stores enormous digitized datasets about “the non-digital world,” such as digitized text, public documents, complex administrative datasets, and records of real world events. This workshop aims to introduce participants to a few practical tools for collecting data from the Internet. After reviewing some of the possibilities that the Internet affords social scientists, we will walk through hands-on examples using Python to collect data from the Internet. In particular, we will cover the basics of working with application programming interfaces (APIs) and the rudiments of web scraping and web crawling. To follow along (which you’re encouraged to do), you will need to install Python on your computer (examples will use Python 2.7). Python is free to download and comes pre-installed on all Mac computers. Familiarity with Python objects will be helpful, but no previous knowledge of programming is required.